




Neueste Artikel aus der Welt der Künstlichen Intelligenz

27 Juli 2026
Jacobian Lens: Was Claude „denkt“ und nicht sagt
Wenn ein Paper über künstliche Intelligenz von „Geist“, „Arbeitsbereich“ und „ungesagten Gedanken“ spricht, haben wir es mit Metaphern zu tun, die nützlich sind, um komplexe Konzepte zugänglich zu machen, aber auch potenziell irreführend für genau das Publikum, dem sie die Dinge eigentlich vereinfachen sollten. Am 6. Juli veröffentlichte Anthropic eine neue Studie, die genau diese Art von Sprache verwendet, und in den folgenden Tagen spaltete sich das Netz in diejenigen, die die Nachricht als Vorzimmer einer bewussten Maschine lasen, und diejenigen, die sie als als Philosophie getarntes Engineering abtaten. Die Wahrheit liegt, wie so oft, in der Mitte, aber um sie zu finden, muss man die Daten sorgfältig von den Worten trennen, die gewählt wurden, um sie zu beschreiben.

24 Juli 2026
Loop Engineering: Trend der Stunde oder der nächste Sprung?
Mitte Juni machte ein Post von Peter Steinberger, einem Entwickler, der für den Aufbau und späteren Verkauf von PSPDFKit bekannt ist, wochenlang die Runde unter Fachleuten: KI-Agenten werden nicht mehr ge-prompt-et, man entwirft die Loops, die sie antreiben. Wenige Zeilen, ein Tonfall wie eine Offenbarung, und innerhalb weniger Tage tauchte der Begriff „Loop Engineering“ überall auf, von Analytics Vidhya bis hin zu Unternehmensblogs, die auf Agenten-Infrastrukturen spezialisiert sind, wie Requesty. Auch Boris Cherny, einer der Architekten von Claude Code, legte nach und sprach von einem Sprung, der mit dem vom kompilierten Quellcode zu autonomen Agenten vergleichbar sei, wie BDTechTalks bei der Rekonstruktion der Entstehungsgeschichte der Debatte berichtet.
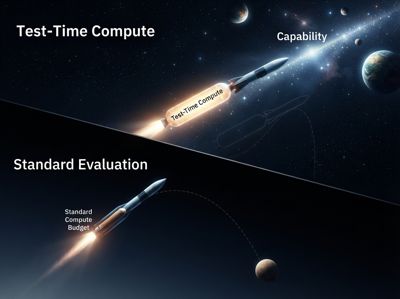
22 Juli 2026
Warum Benchmarks für KI-Agenten die realen Fähigkeiten unterschätzen
Jahrelang haben wir die Fähigkeit eines KI-Agenten wie eine feste Zahl behandelt, fast wie die Zeit eines Hundertmeterläufers: Man rennt, man stoppt die Zeit, man schreibt das Ergebnis auf eine Tafel. Aber was, wenn diese Zahl von dem Atem abhängt, den wir dem Läufer zugestehen, bevor wir ihn stoppen? Ein am 2. Juli 2026 vom AI Security Institute veröffentlichter Bericht, dem KI-Sicherheitsinstitut der britischen Regierung, legt nahe, dass genau dies der versteckte Fehler in vielen Agenten-Bewertungen ist: Wir stoppen sie mit einer Pfeife, die zu früh ertönt.

20 Juli 2026
Colibrì: Die Mini-Engine, die ein 744B-Modell auf Consumer-Hardware ausführt
Jede Woche scheint die lokale Open-Source-KI-Community ihr Lieblingsthema zu suchen, und in der vergangenen Woche fiel die Wahl offenbar auf ein GitHub-Repository mit einem kuriosen Namen und einem fast absurden Versprechen: GLM-5.2, ein Mixture-of-Experts-Modell mit 744 Milliarden Parametern, auf einem Computer mit gerade einmal 25 GB RAM laufen zu lassen. Das Projekt heißt Colibrì und ist das Werk eines einzelnen Entwicklers, JustVugg, der im Danksagungsabschnitt seiner README mit entwaffnender Ehrlichkeit zugibt, alles auf einem Laptop mit zwölf Kernen geschrieben und getestet zu haben. Kein Labor, kein Cluster, kein Hardware-Sponsoring. Nur eine bis zum Ende durchgezogene technische Obsession.

17 Juli 2026
DSpark: DeepSeeks Wette auf Geschwindigkeit, die die Qualität nicht verrät
DeepSeek hat nicht nur einen neuen Ansatz für speculative decoding vorgestellt; mit DeepSpec versuchen sie, diesen in eine reproduzierbare industrielle Pipeline zu verwandeln. Das Paper trägt den Titel DSpark, das Kürzel ist das x-te in einer langen Reihe, die das chinesische Labor fast vierteljährlich herausbringt, und die Versuchung ist groß, es nur flüchtig zu überfliegen. Das wäre ein Fehler, denn hinter dem Akronym verbirgt sich eine sehr konkrete Frage: Wie sehr kann die Inferenz eines Sprachmodells wirklich beschleunigt werden, wenn das Modell, das die Antwortentwürfe generiert, aufhört, naiv zu sein, und wenn das System, das sie kontrolliert, lernt, keine Zeit mit denen zu verschwenden, die für den Papierkorb bestimmt sind.

15 Juli 2026
Ich habe der KI das Wachehalten beigebracht: Wie ich ein Sicherheitssystem zum Nulltarif gebaut habe
In der Fernsehserie 'Person of Interest' überwacht eine Superintelligenz, die einfach nur "die Maschine" genannt wird, jeden Winkel des Planeten durch Kameras, Mikrofone und Sensoren aller Art und erkennt Bedrohungen, bevor sie entstehen. Das ist natürlich Science-Fiction. Aber die Grundidee, nämlich Computer Vision zu nutzen, um zu verstehen, was in einer Umgebung passiert, ist heute für jeden zugänglich, der einen PC und eine Webcam besitzt. Weniger als 250 Zeilen Code. Kein Abonnement, keine Cloud, kein Video, das um die Welt geht. Nur eine Benachrichtigung auf dem Telefon, mit Foto, wenn jemand das Haus betritt.

13 Juli 2026
Die KI rennt, die Welt geht: Was der erste wissenschaftliche UN-Bericht sagt
In Serial Experiments Lain gibt es eine Szene, in der die Protagonistin entdeckt, dass das Netzwerk, mit dem sie schon immer verbunden war, aufgehört hat, ein Werkzeug zu sein, und zu einer Umgebung wird – etwas, das sie einschließt und definiert, ohne dass jemals jemand bewusst entschieden hätte, dass dies geschieht. Beim Lesen des ersten unabhängigen wissenschaftlichen Berichts der Vereinten Nationen über künstliche Intelligenz drängt sich genau dieses Gefühl auf: ein System, das sich schneller ausgedehnt hat als unsere Fähigkeit, es zu beschreiben, und nun versucht endlich jemand, dies methodisch zu tun.

10 Juli 2026
Ornith-1.0 35B lokal: Der Unbekannte, der alle schlägt
Es gibt in jeder Sitzung mit einem neuen lokal heruntergeladenen Modell diesen Moment, in dem man begreift, ob man ein Spielzeug oder ein Arbeitsgerät vor sich hat. Bei Ornith-1.0-35B kam dieser Moment beim zweiten Prompt, als ich das unscharfe Foto einer betrieblichen Excel-Tabelle hochlud und die übliche vage Antwort erwartete, stattdessen aber eine echte Bilanzanalyse erhielt, inklusive Warnsignalen zur Liquidität. Von da an nahm die Test-Session eine andere Wendung als üblich.

08 Juli 2026
GLM-5.2: das chinesische Open-Weight-Modell, das die Lücke schließt, zumindest beim Coding
Als Z.ai, das Labor, das in China jeder noch als Zhipu AI kennt, im vergangenen Februar GLM-5 veröffentlichte, war die Botschaft bereits klar: Die GLM-Serie zielte nicht darauf ab, einfach nur wettbewerbsfähig zu sein, sie zielte darauf ab, für Softwareentwickler relevant zu sein. Dieses Modell mit 744 Milliarden Parametern und Mixture-of-Experts-Architektur hatte Leistungen auf den Tisch gelegt, die sich neben den großen proprietären Modellen nicht verstecken mussten, mit dem alles andere als nebensächlichen Unterschied der offenen Gewichte unter MIT-Lizenz. Etwas mehr als vier Monate später, am 13. Juni 2026, hat Z.ai den Einsatz erneut erhöht: GLM-5.2 erschien zuerst auf den Tiers des GLM Coding Plan, den Abonnementplänen für Entwickler, und dann am 16. Juni über die öffentliche API und auf Hugging Face mit frei herunterladbaren Gewichten.

06 Juli 2026
Brauchen Sie wirklich das neueste KI-Modell? Oder aktualisieren Sie nur Ihr technologisches Ego?
Brauchen Sie wirklich das neueste State-of-the-Art-Modell für Ihre tägliche Arbeit? Wenn Ihre Antwort "Ja" lautet, sind Sie sicher, dass Sie nicht vom Marketing der Big-Tech-Unternehmen getäuscht wurden? Anthropic hat gerade Claude Opus 4.8 auf den Markt gebracht, OpenAI arbeitet bereits an der nächsten Version von ChatGPT, und alle drängen uns dazu, dem neuesten Modell hinterherzujagen, als hinge unsere Produktivität von der letzten Dezimalstelle eines Benchmarks ab. Dabei kostet ein effizientes Modell wie zum Beispiel DeepSeek V4 Flash für 90 % der täglichen Aktivitäten nur einen Bruchteil des Preises und macht genau das Gleiche. Kommt Ihnen das bekannt vor? Mir schon, und ich werde versuchen, es Ihnen zu erzählen.

03 Juli 2026
Headroom: Der Token-Kompressor, der keine KI nutzt, um KI zu komprimieren
Im Herzen vieler moderner KI-Systeme verbirgt sich ein stilles Paradoxon. Ingenieure bauen hochentwickelte Agenten, die in der Lage sind, komplexe Handlungssequenzen zu durchdenken, zu planen und zu koordinieren. Dann schauen sie auf die monatliche API-Rechnung und stellen fest, dass die größte Ausgabe nicht das Denken, nicht die Kreativität und nicht einmal die Genauigkeit ist. Es ist der Traffic. Das reine, banale Volumen an Text, das die Komponenten untereinander austauschen.

01 Juli 2026
Last30days: Wenn ein Code-Agent zur sozialen Suchmaschine wird
Bevor ich etwas über KI schrieb, öffnete ich elf Browser-Tabs: Reddit, X, YouTube, Hacker News, GitHub, ein paar Branchen-Newsletter. Zwei Stunden später, nach drei Kaffees, hatte ich drei wirklich nützliche Posts gefunden. Der Rest war Rauschen: für Suchmaschinen optimierte Blogartikel, Meinungen von Menschen, die dafür bezahlt wurden, sie zu haben, klassische Galerien nach dem Motto „Die zehn KI-Tools, die Ihr Leben verändern werden“, geschrieben mit der gleichen Tiefe wie ein Montageblatt für IKEA-Möbel.

29 Juni 2026
Die KV-Cache und das Gewicht der Aufmerksamkeit: drei Wege, ein Problem
Llama-3.1-70B, ausgeführt in BF16-Präzision, sammelt etwa 0,31 Megabyte KV-Cache für jeden einzelnen verarbeiteten Token an. Bei einem Kontext von 128.000 Token steigt die Rechnung auf 40 Gigabyte, eine bereits ungemütliche Zahl. Bei einer Million Token, dem Standard, auf den die neuesten Modelle zusteuern, werden mehr als 300 Gigabyte überschritten: mehr als die 140 Gigabyte, die von den Gewichten des Modells selbst belegt werden. Es ist ein Detail, das eine weit verbreitete Intuition umkehrt, nämlich dass der kritische Speicher in einem großen Sprachmodell der seiner Parameter sei. Das ist nicht mehr so, oder zumindest nicht immer. Der Speicher, der diejenigen, die Inferenzsysteme mit langem Kontext entwerfen, wirklich erschreckt, ist der der KV-Cache, das Archiv, in dem das Modell die Key- und Value-Repräsentationen jedes bereits gesehenen Tokens aufbewahrt, um nicht für jedes neue generierte Wort alles von Grund auf neu berechnen zu müssen.

26 Juni 2026
Kurse zugunsten von KI gestrichen: China schreibt die Universität neu
Es gibt eine Szene, die von der South China Morning Post erzählt wird und mehr wert ist als tausend Statistiken: Ein Absolvent des Industriedesigns erklärt, dass sein Kurs eingestellt wurde, weil die künstliche Intelligenz genau diesen Sektor hart getroffen hat, in dem Modellierung und Rendering mittlerweile größtenteils oder vollständig von einem Algorithmus durchgeführt werden können. Dies ist kein Einzelfall, sondern das Symptom einer Transformation, die das gesamte chinesische Universitätssystem in wenigen Jahren und mit einer Entschlossenheit durchlaufen hat, die im Westen ihresgleichen sucht.

24 Juni 2026
Der algorithmische Krieg. Fable 5 der Finger, Europa der Mond
Am 12. Juni 2026 sandte das US-Handelsministerium einen Brief an Anthropic, der in den Kreisen der Branche mit der Geschwindigkeit von Nachrichten kursierte, die wirklich Angst machen: obligatorische Suspendierung der Modelle Fable 5 und Mythos für jeden ausländischen Staatsbürger, innerhalb oder außerhalb der amerikanischen Grenzen. Die offizielle Begründung ist die nationale Sicherheit. Peking-nahe Gruppen sollen sich unter Umgehung der Zugangskontrollsysteme Zugang zu Mythos verschafft haben, der Version ohne Guardrails (Schutzplanken), die für Cybersicherheitsanwendungen konzipiert wurde. Eine schwerwiegende Verletzung, falls sie bestätigt wird, zweifellos. Aber bei dieser Nachricht stehen zu bleiben, wie es viele tun, besessen von den Namen Fable 5 und Mythos, als wären sie Charaktere aus einer dystopischen Serie, ist so, als würde man auf den Finger schauen und nicht auf den Mond.

22 Juni 2026
BenzUp: Ich habe eine App erstellt, ohne eine einzige Zeile Code zu schreiben
Es gibt einen präzisen Moment, in dem eine Idee aufhört, eine Kneipenfantasie zu sein, und zu etwas Konkretem wird. In meinem Fall waren die Hauptdarsteller dieses Moments in dieser Reihenfolge: die Benzinpreise, ein amerikanischer Ingenieur, der sich über ein teures Bier in Dublin ärgerte, und ein KI-Modell, das für jeden mit einer Internetverbindung zugänglich ist. Das Ergebnis heißt BenzUp, ist kostenlos, macht nichts Revolutionäres, und vielleicht ist es genau deshalb erzählenswert.